

We analyzed 80,141 English humanization pairs from WriteHuman, a random sample drawn from submissions over the last 60 days. Every statistic here is aggregate; no user-submitted text is quoted anywhere in this report.
The short version
The iconic AI tell is no longer iconic. In 80,141 recent humanization pairs, only 18.5% of AI inputs contain an em-dash. Still a signal, but far from the "everything is em-dashes" caricature, and dwarfed by what does give AI away now.
The strongest single word that signals "AI wrote this" is ensuring, over-represented 4.3× in AI inputs relative to humanized versions. Behind it: a family of hedging verbs ("ensures," "highlights," "supports," "reflects") that ChatGPT reaches for when it's padding an idea to sound considered.
The strongest phrase is "rather than", appearing 17,251× in AI inputs vs 6,859× in humanized outputs. It's how ChatGPT hedges a comparison instead of making one.
The real 2026 AI tells are structural, not vocabulary. The single most formulaic thing ChatGPT produces, statistically, is the sentence shape "X plays a crucial/critical/important role in shaping Y", which dominates the top of our trigram rankings.
Detection moves a lot. On a separate 400-input test, the average GPTZero AI-probability dropped from 73.7% to 4.0% after one pass through our humanizer. That's a 69.7 percentage-point drop. 70.8% of inputs that started above GPTZero's "more likely AI than human" 50% line ended up below it.
Part 1: What actually signals "AI wrote this" in 2026
"Watch for the em-dashes." That's been the 2024–2025 rule for spotting ChatGPT, the iconic punctuation tell that launched a thousand think-pieces and quite a few reddit jokes. It's not wrong, exactly. Our data says em-dashes are still a real signal: 18.5% of AI inputs contain at least one, versus 7.1% of the humanized versions. But that's a 2.6× effect: meaningful, not overwhelming. And it's drastically smaller than what we found when we looked at words and phrases.
The real 2026 AI tells are quieter and more structural. They're about rhetorical posture and sentence shape, not punctuation or vocabulary flair.
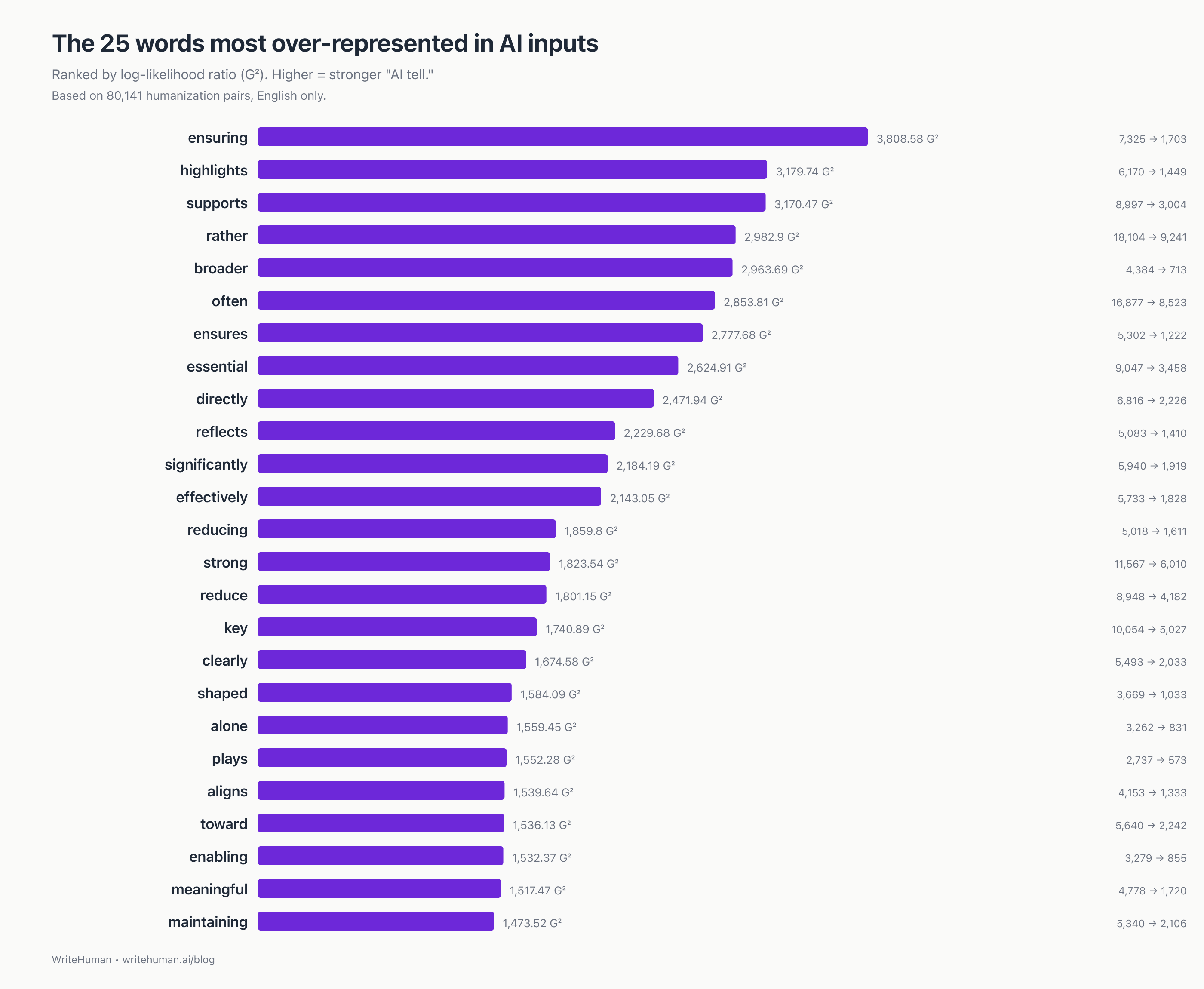
The 15 single-word tells
Rank | Word | G² | In AI inputs | In humanized outputs |
|---|---|---|---|---|
1 | ensuring | 3,808.58 | 7,325 | 1,703 |
2 | highlights | 3,179.74 | 6,170 | 1,449 |
3 | supports | 3,170.47 | 8,997 | 3,004 |
4 | rather | 2,982.9 | 18,104 | 9,241 |
5 | broader | 2,963.69 | 4,384 | 713 |
6 | often | 2,853.81 | 16,877 | 8,523 |
7 | ensures | 2,777.68 | 5,302 | 1,222 |
8 | essential | 2,624.91 | 9,047 | 3,458 |
9 | directly | 2,471.94 | 6,816 | 2,226 |
10 | reflects | 2,229.68 | 5,083 | 1,410 |
11 | significantly | 2,184.19 | 5,940 | 1,919 |
12 | effectively | 2,143.05 | 5,733 | 1,828 |
13 | reducing | 1,859.8 | 5,018 | 1,611 |
14 | strong | 1,823.54 | 11,567 | 6,010 |
15 | reduce | 1,801.15 | 8,948 | 4,182 |
Three patterns emerge:
1. Hedging verbs. "ensuring," "ensures," "highlights," "supports," "reflects." ChatGPT reaches for these when it's padding an idea to sound considered. A human would just say what the thing does.
2. Intensifier adverbs. "significantly," "effectively," "directly," "strong," "increasingly." Vocabulary of implication without evidence. If you can't back the intensifier with a number, the sentence doesn't need it.
3. Relational connectors. "rather," "broader," "reducing." Glue between ideas that often doesn't need to exist.
The AI phrasebook (2026 edition)
Phrases make the pattern unmistakable:
Rank | Phrase | G² |
|---|---|---|
1 | "rather than" | 5,939.78 |
2 | "such as" | 4,390.56 |
3 | "role in" | 3,436.19 |
4 | "long term" | 2,567.12 |
5 | "essential for" | 2,121.7 |
6 | "ensuring that" | 1,791.67 |
7 | "shaped by" | 1,691.95 |
8 | "ensures that" | 1,388.41 |
9 | "highlights the" | 1,323.85 |
10 | "while maintaining" | 1,269.54 |
"rather than" is the strongest single multi-word tell in the entire dataset. It's how ChatGPT hedges a comparison instead of making one.
Trigrams give up the formula entirely:
Rank | Phrase | G² |
|---|---|---|
1 | "is essential for" | 1,348.99 |
2 | "and long term" | 1,254.75 |
3 | "role in shaping" | 911.72 |
4 | "crucial role in" | 860.09 |
5 | "critical role in" | 809.88 |
6 | "this paper introduces" | 789.17 |
7 | "important role in" | 686.04 |
8 | "rather than relying" | 685.37 |
9 | "understanding of how" | 677.78 |
10 | "aligns well with" | 654.35 |
Read the top 5 aloud. "is essential for," "and long term," "role in shaping," "crucial role in," "critical role in." That's the cadence of ChatGPT's academic register. The sentence shape "X plays a crucial/critical/important role in shaping Y" is, statistically, the single most formulaic thing ChatGPT produces in our data.
What humans add back
When text gets humanized, some words appear much more in the output than the input. These are the words people (or a well-trained humanizer) reach for when scrubbing AI:
able: appears 12,227× in humanized outputs vs. 2,929× in AI inputs (4.2× more common in human edits)
case: appears 15,402× in humanized outputs vs. 6,234× in AI inputs (2.5× more common in human edits)
order: appears 11,121× in humanized outputs vs. 3,894× in AI inputs (2.9× more common in human edits)
various: appears 8,555× in humanized outputs vs. 3,006× in AI inputs (2.8× more common in human edits)
assist: appears 5,100× in humanized outputs vs. 1,237× in AI inputs (4.1× more common in human edits)
great: appears 5,654× in humanized outputs vs. 1,649× in AI inputs (3.4× more common in human edits)
positive: appears 13,768× in humanized outputs vs. 6,960× in AI inputs (2.0× more common in human edits)
appreciate: appears 4,893× in humanized outputs vs. 1,292× in AI inputs (3.8× more common in human edits)
along: appears 5,513× in humanized outputs vs. 1,637× in AI inputs (3.4× more common in human edits)
thus: appears 5,653× in humanized outputs vs. 1,751× in AI inputs (3.2× more common in human edits)
The standout is able. It's the shortest, simplest edit in the whole dataset, and it's everywhere. Wherever AI writes "capable of X," "positioned to X," "suited for X," the humanizer reliably swaps in "able to X." That single word is the signature move of humanization.
Part 2: The proof it works
Words are interesting. But does editing them actually move a detector?
We took 400 real AI-generated inputs from our platform (English, 100–300 words, last 30 days), ran each through our humanizer to generate 3 variations per input, then scored every version (input + all three variations) with GPTZero. For each input we took the best of three (the lowest AI-probability variation, as our Pro and Ultra plans allow for), because that's what the product surfaces to users.
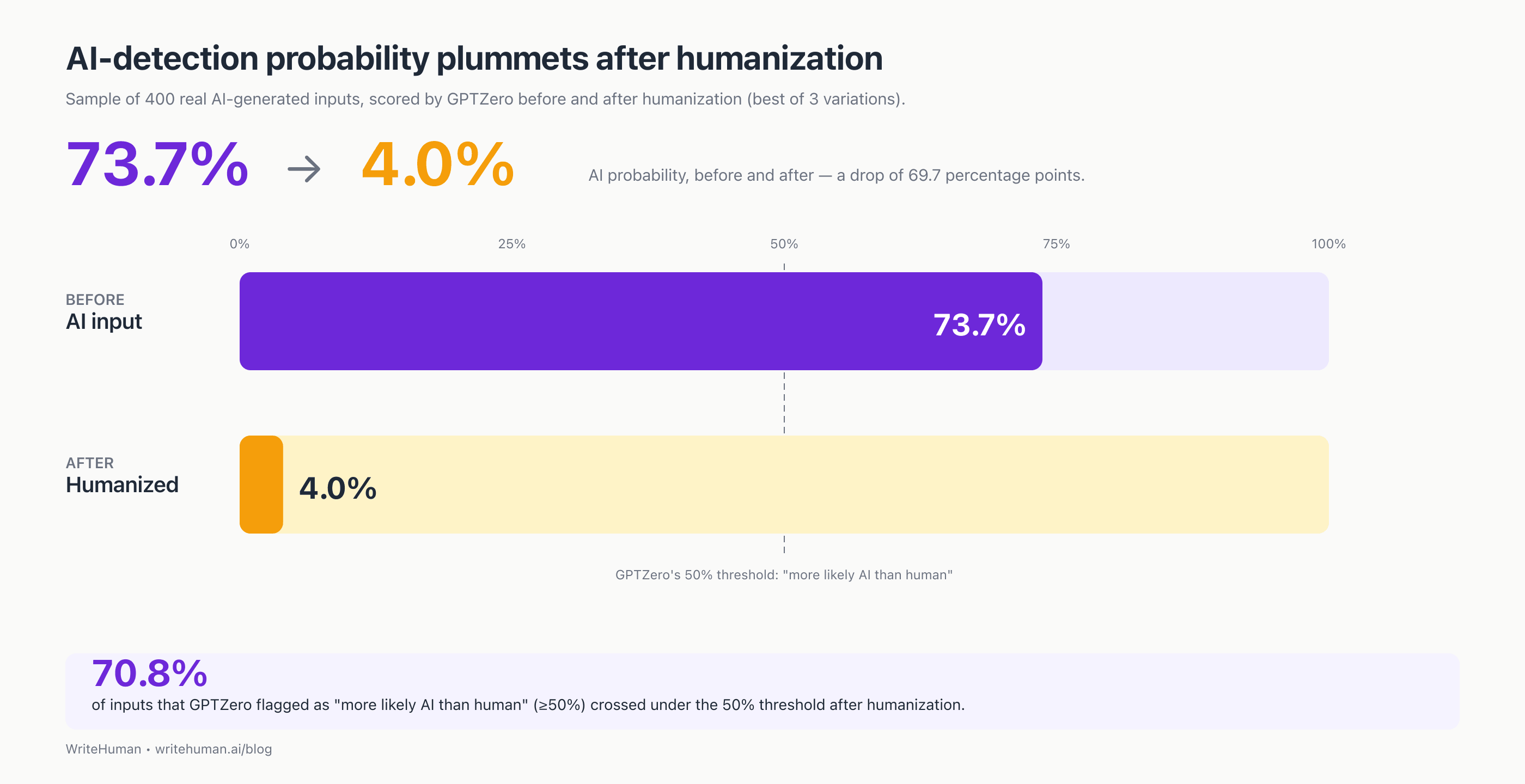
GPTZero AI-probability | |
|---|---|
Raw AI input (average) | 73.7% |
Humanized output, best of 3 (average) | 4.0% |
Drop | 69.7 pp |
70.8% of inputs that GPTZero flagged as "more likely AI than human" (≥50% probability) dropped under the 50% line after humanization.
One methodology note worth publishing: among the 3 variations, which one scores best is essentially random, although it can be influenced by our internal AI detector. Across 400 inputs, the winning variation was roughly uniform across slots 1 / 2 / 3. There's no "the first one is always best" shortcut. Running multiple and picking the winner is genuinely the right play.
Part 3: What we expected to find but didn't
Three findings to publish in the spirit of not cherry-picking.
Em-dashes are a weaker tell than the narrative claims
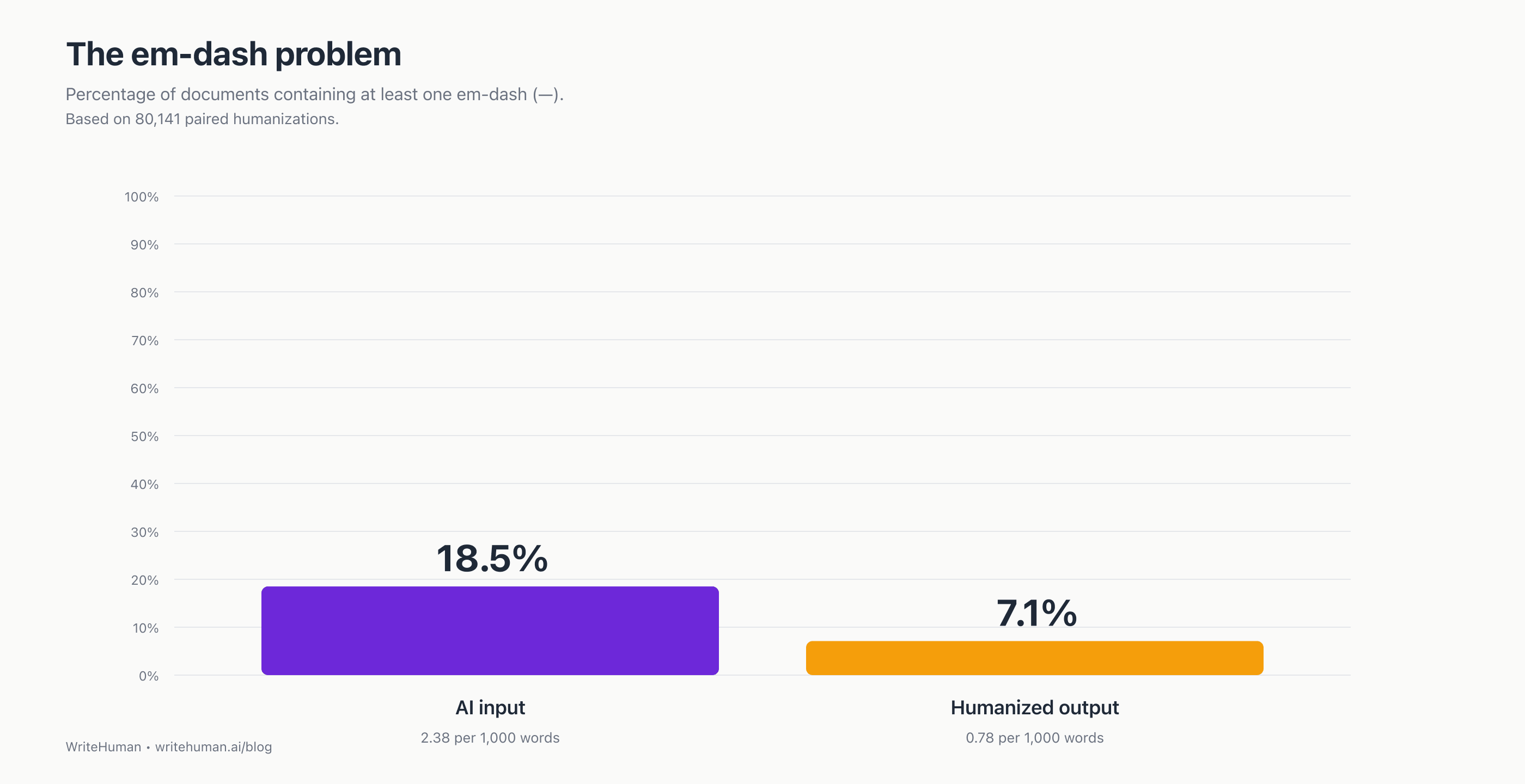
The 2024 consensus said ChatGPT uses em-dashes constantly. Our 2026 data says only partly:
18.5% of AI inputs contain at least one em-dash. That's meaningful, since most human prose contains almost none, but far from the "everything has em-dashes" caricature.
7.1% of humanized outputs contain at least one. So the humanizer does strip them.
When an AI input does contain em-dashes, the humanized version strips all of them 67.2% of the time.
So em-dashes are still a signal, just a secondary one. OpenAI appears to have dialed back em-dash use in recent model generations.
Humanized text is slightly longer per sentence, not shorter
AI input averages 22.9 words per sentence; humanized output averages 23.3 words per sentence. A small difference, but the direction is the surprise. Our humanizer adds natural connective tissue, not the staccato compression people assume humanization means.
Semicolons are not a tell
AI input uses semicolons at 1.18 per 1,000 words; humanized output at 1.10 per 1,000. Effectively identical. Tricolons ("X, Y, and Z" patterns) show a modest reduction from 4.39 to 3.74 per 1,000 words, but nothing like the 10× effect you'd need for a headline.
How to edit AI text so it sounds less like AI
Distilled from the data:
Cut "rather than." The strongest single multi-word edit in the dataset. Rewrite the comparison directly or drop the qualifier.
Replace "capable of X" with "able to X." The single highest-leverage word substitution. It's what the humanizer does more than any other edit.
Strip "plays a [crucial / critical / important] role in shaping." This construction dominates the top trigrams across variants.
Break formulaic openers. "This paper introduces…", "In recent years…", "Understanding of how…" are template scaffolding that signals AI.
Cut the hedging verbs. Replace ensures, ensuring, highlights, supports, reflects with concrete verbs, or delete them.
Kill the intensifiers. significantly, effectively, increasingly are padding unless you can back them with a number.
Em-dashes: optional cleanup. If you see one and it doesn't feel natural, delete it. 67% of the time, the humanizer does (67, anyone? Sorry.).
Methodology
Corpus: random sample of 80,141 English humanization pairs drawn from English submissions over the last 60 days. Authenticated users capped at 5 submissions in the sample to prevent single-customer templates from dominating the rankings.
Statistic: log-likelihood ratio (G², Dunning 1993), the standard statistic for corpus-vs-corpus comparison. Positive G² = over-represented in AI inputs; negative = over-represented in humanized outputs.
Filters: English only; inputs and outputs each ≥ 120 characters; unigrams ≥ 50 total occurrences; n-grams ≥ 20 joint occurrences; standard English stopword list plus a small WriteHuman-specific augment.
Detection drop: separate sample of 400 real AI-generated inputs (English, 100–300 words, last 30 days) run through WriteHuman's latest fine-tuned humanizer model with 3 variations per input. Every input and every variation scored with GPTZero. Reported "after" probability is the best (lowest) of the 3 variations.
Privacy: Aggregate statistics only; no user-submitted text is quoted or reproduced anywhere in this report.
Known limitation: WriteHuman's user base skews toward business and research writing. Findings generalize strongly to formal English prose, moderately to marketing copy, less so to casual writing or dialogue.
Report generated: 2026-04-21.


